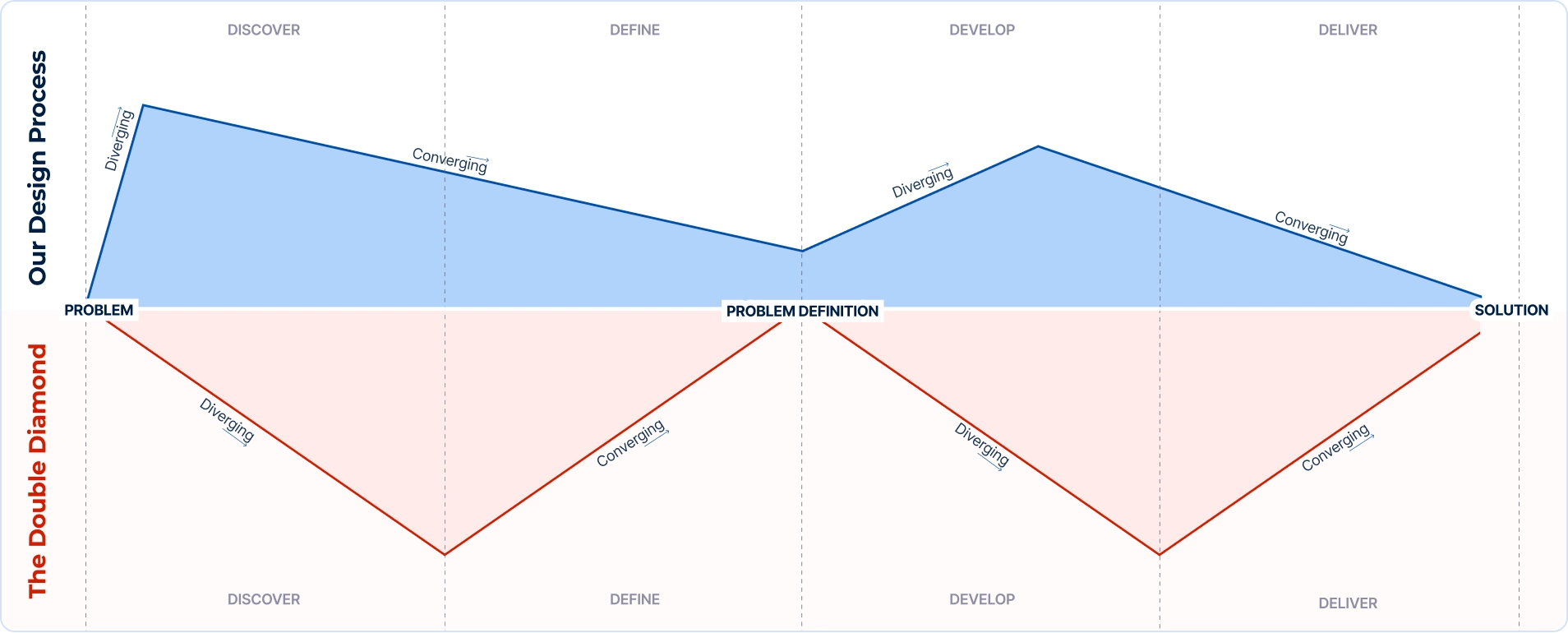
Exploring our approach to projects and how we've adapted the Double Diamond methodology to create a flexible UX design process
Continue reading
We recently observed a significant spike in crawling activity from the bots of Facebook, Amazon, and Bytedance. The sheer volume of traffic generated by these three bots in just one day severely impacted the performance of our servers, leading to noticeable disruptions for some of our clients.
It seems these tech giants are aggressively trying to amass as much data as possible to fuel their large language models (LLMs) in an effort to keep pace with the advancements in AI, like those seen with ChatGPT. Unfortunately, this relentless data gathering appears to be conducted without regard for the collateral damage inflicted on other web services.
Assuming others are facing similar challenges, we decided to share some insights here that might prove helpful.
Our choice to resolve this challenge was our old friend Fail2Ban, a tool we have used since the beginning and found invaluable in blocking threats. Fail2Ban works by monitoring log files and banning IPs that show malicious signs—such as too many password failures, seeking exploits, etc.—and now, in our case, it helps manage excessive bot traffic.
Fail2Ban is a log-parsing application that scans server logs for specific patterns and takes action based on predefined rules. It's widely used to protect against brute force attacks and to mitigate DDoS threats by temporarily banning offending IP addresses. The flexibility of Fail2Ban allows it to be configured for various security scenarios, making it a robust solution for server protection.
Today, we noticed performance degradation in some of our services, and upon analysis, we found that the majority of non-user-generated traffic was caused by the Bytedance, Facebook, and Amazon bots. Here are the links to their respective bot pages:
Upon further inspection, we checked the IP ranges from which the traffic was originating and confirmed that all addresses were legitimate and listed on the respective bots' pages. So, instead of it being a DDoS attack, it was legitimate bot traffic, unfortunately. Since our clients do not benefit much from these bots, and the offensive traffic was generating more than 1 GB of access log data per day, we decided to reduce the availability of our servers to them to manage the traffic and lighten the load.
Below is the sample from our access logs for each bot:
47.128.56.213 - - [27/Jun/2024:00:47:21 +0200] "GET /search/type/apartment/page/5/type/apartment/page/8/type/apartment?page=9&type=apartment HTTP/2.0" 200 8375 "-" "Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; spider-feedback@bytedance.com)" 69.171.249.13 - - [27/Jun/2024:06:50:21 +0200] "GET /it/search/page/1/page/4/page/2/page/4/page/3/page/2/page/4/page/5 HTTP/2.0" 200 80235 "-" "facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)" 23.22.35.162 - - [27/Jun/2024:02:45:00 +0200] "GET /search/page/14/page/6/page/14/page/13/page/5/page/2/page/1/page/3/page/4/page/5/page/6/page/9/page/13/page/9/page/10/page/12/page/11/page/11/page/11/page/10/page/12/page/10/page/11/page/11?page=12 HTTP/1.1" 403 117 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)"
1. Create a Jail Configuration:
Create a new jail configuration file in the jail.d directory.
sudo vi /etc/fail2ban/jail.d/webbots.conf
Add the following content to the file:
[webbot] enabled = true port = http,https filter = facebookbot logpath = /var/log/nginx/access.log maxretry = 20 findtime = 600 bantime = 3600
This will allow us to grant the bot access, but limit the amount of requests the bot can make to 20 within 10 minutes, and if the limit is exceded it will ban the specific IP from accesing the server for the period of 1 hour. What you need to keep in mind is that facebook, and other companies use a large ammount of servers with different ips to do the crawling, so we are just preventing this specific ip for a short period of time. It will not fully block facebookg bot fro accesing the page, and it will make much more then 20 requests within 10 minutes using multiple ips.
2. Create a Filter for the Bots:
Create a filter configuration file in the filter.d directory.
sudo vi /etc/fail2ban/filter.d/webbots.conf
Add the following content to the file:
[Definition] failregex =.*\"GET.*HTTP/.*\".*Amazonbot .*\"GET.*HTTP/.*\".*facebookexternalhit/1.1 .*\"GET.*HTTP/.*\".*Bytespider ignoreregex =
3. Restart Fail2Ban & Verify the configuration is working::
After creating or modifying the configuration files, restart the Fail2Ban service to apply the changes. And check the status of Fail2Ban to ensure the webbots jail is active and correctly configured.
sudo systemctl restart fail2ban sudo fail2ban-client status webbots
The output should look something like this:
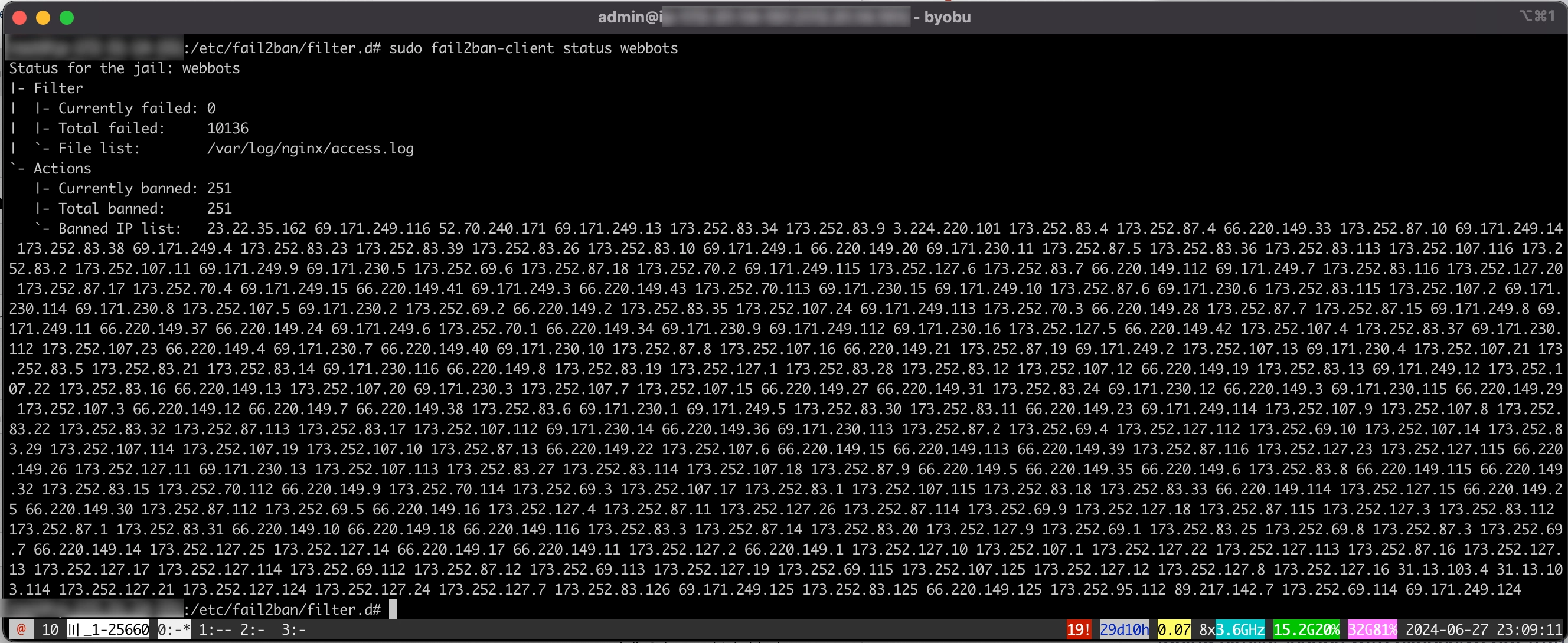
By implementing these steps, we were able to manage and throttle the bot traffic effectively, ensuring that our clients’ services remained stable and performant. This approach can help others facing similar issues with excessive bot traffic, providing a practical solution to maintain server health and user experience.
Spread the knowledge and share this post




